+
A checklist in the README doesn't work. Humans skip checklists. Code review catches some issues but not all — reviewers focus on logic, not whether a URL points to a deleted org.
+
We built a pre-commit hook with two layers: a regex blocklist that's instant and free, and an LLM review that costs $0.001. Together they catch everything.
+
Layer 1: Regex blocklist (0ms, $0.00)
+
A text file of patterns, each tagged with scope and message:
+
public|\b<internal-codename>\b|Classified codename — use the public-facing alias
all|github\.com/(tinqs-ltd|tinqs)/|GitHub repos deleted — use tinqs.com
all|sk-[a-zA-Z0-9]{20,}|Possible API key leaked
all|AKIA[A-Z0-9]{16}|AWS access key leaked
-public|admin\.|Internal admin URL in public content
-`
-
-The scope field controls where patterns apply. all means every file. public means only public-facing content — blog posts, website, marketing pages. We want classified codenames in internal architecture docs. We just don't want them in blog posts.
-
-The blocklist runs grep against the staged diff. No network call, no API, no latency. Match found → commit blocked immediately with file path and explanation. This catches 80% of issues before the LLM wakes up.
-
-## Layer 2: DeepSeek V4 Flash review (~4s, $0.001)
-
-If the commit touches public-facing files, the hook sends the staged diff to DeepSeek V4 Flash. The system prompt tells it exactly what to check:
-
-- Leaked secrets — API keys, tokens, credentials the regex might have missed
-- Classified terms — codenames not yet in the blocklist
-- Internal URLs — references to services that shouldn't be public
-- Blog quality — title length, meta description, slug consistency
-- Broken links — malformed URLs, obvious typos
-- Announcements — if it's a new blog post, draft a one-line summary
-
-The model responds with structured JSON: errors (block) or warnings (inform but allow). If the API is unreachable or times out, the commit proceeds — the hook never blocks work for infrastructure reasons.
-
-## The architecture
-
-`
-git commit
+public|admin\.<internal-domain>|Internal admin URL in public content
+
The scope field controls where patterns apply. all means every file. public means only public-facing content — blog posts, website, marketing pages. We want classified codenames in internal architecture docs. We just don't want them in blog posts.
+
The blocklist runs grep against the staged diff. No network call, no API, no latency. Match found → commit blocked immediately with file path and explanation. This catches 80% of issues before the LLM wakes up.
+
Layer 2: DeepSeek V4 Flash review (~4s, $0.001)
+
If the commit touches public-facing files, the hook sends the staged diff to DeepSeek V4 Flash. The system prompt tells it exactly what to check:
+
+ - Leaked secrets — API keys, tokens, credentials the regex might have missed
+ - Classified terms — codenames not yet in the blocklist
+ - Internal URLs — references to services that shouldn't be public
+ - Blog quality — title length, meta description, slug consistency
+ - Broken links — malformed URLs, obvious typos
+ - Announcements — if it's a new blog post, draft a one-line summary
+
+
The model responds with structured JSON: errors (block) or warnings (inform but allow). If the API is unreachable or times out, the commit proceeds — the hook never blocks work for infrastructure reasons.
+
The architecture
+
git commit
↓
Phase 0: Collect staged diff + classify files (public vs internal)
↓
@@ -331,52 +319,33 @@ Phase 3: Parse JSON response
→ Errors → BLOCK
→ Warnings → print, exit 0
→ Announcement → print draft
- → API failure → warn, exit 0 (never block on infra)
-`
-
-The hook lives in .githooks/ — committed, version-controlled, shared by the team. A setup script points git config core.hooksPath there.
-
-## What it costs
-
-| | Tokens | Cost |
-|–|——–|——|
-| Input (prompt + diff) | ~4,000 | $0.00056 |
-| Output (JSON response) | ~200 | $0.00006 |
-| Per commit | | $0.00062 |
-
-A tenth of a cent. Twenty commits a day: $0.012/day. About $0.40/month. Commits that only touch internal files skip the AI review entirely — zero cost.
-
-## What it caught (first week)
-
-- 2 classified codename leaks in draft blog posts — caught by blocklist
-- 1 GitHub URL from an old copy-paste — caught by blocklist
-- 3 blog SEO warnings — titles over 60 chars, missing og_description — caught by AI
-- 1 announcement draft auto-generated when a new post was committed
-
-Zero false positives on the blocklist. Two false positives from the AI — flagged an internal URL in a code example that was clearly illustrative. We added a note to the prompt: ignore URLs inside fenced code blocks.
-
-## Setup
-
-`bash
-bash scripts/setup-hooks.sh # or .\scripts\setup-hooks.ps1 on Windows
-export TINQS_HOOK_TOKEN= # same PAT used for git push
-`
-
-That's it. Every git commit runs the two-layer review. Bypass with git commit –no-verify` for emergencies.
-
-## The pattern: guard rails at the edge
-
-This is the same principle we apply everywhere: put the guard rail where the action happens. Don't rely on a human checklist. Don't wait for code review. Don't hope someone remembers.
-
-The pre-commit hook is $0.001 of prevention. A leaked API key in a public post is hours of rotation, revocation, and audit. A classified codename in a blog post is a confidentiality breach. A dead link is a broken experience nobody notices for weeks.
-
-The tools exist. DeepSeek V4 Flash is cheap enough to call on every commit. The hook is 150 lines of bash. The blocklist is a text file. Total infrastructure cost: zero — it runs on the developer's machine, calls an API we already pay for, adds 4 seconds to the commit flow.
-
-—
-
-The pre-commit hook is part of Tinqs Studio. The inference proxy, blocklist patterns, and review prompt are open and reusable. Every commit in Ariki runs through the same guard.
-
-
+ → API failure → warn, exit 0 (never block on infra)
+
The hook lives in .githooks/ — committed, version-controlled, shared by the team. A setup script points git config core.hooksPath there.
+
What it costs
+
| | Tokens | Cost |
+
|–|——–|——|
+
| Input (prompt + diff) | ~4,000 | $0.00056 |
+
| Output (JSON response) | ~200 | $0.00006 |
+
| Per commit | | $0.00062 |
+
A tenth of a cent. Twenty commits a day: $0.012/day. About $0.40/month. Commits that only touch internal files skip the AI review entirely — zero cost.
+
What it caught (first week)
+
+ - 2 classified codename leaks in draft blog posts — caught by blocklist
+ - 1 GitHub URL from an old copy-paste — caught by blocklist
+ - 3 blog SEO warnings — titles over 60 chars, missing og_description — caught by AI
+ - 1 announcement draft auto-generated when a new post was committed
+
+
Zero false positives on the blocklist. Two false positives from the AI — flagged an internal URL in a code example that was clearly illustrative. We added a note to the prompt: ignore URLs inside fenced code blocks.
+
Setup
+
bash scripts/setup-hooks.sh # or .\scripts\setup-hooks.ps1 on Windows
+export TINQS_HOOK_TOKEN=<your-token> # same PAT used for git push
+
That's it. Every git commit runs the two-layer review. Bypass with git commit –no-verify for emergencies.
+
The pattern: guard rails at the edge
+
This is the same principle we apply everywhere: put the guard rail where the action happens. Don't rely on a human checklist. Don't wait for code review. Don't hope someone remembers.
+
The pre-commit hook is $0.001 of prevention. A leaked API key in a public post is hours of rotation, revocation, and audit. A classified codename in a blog post is a confidentiality breach. A dead link is a broken experience nobody notices for weeks.
+
The tools exist. DeepSeek V4 Flash is cheap enough to call on every commit. The hook is 150 lines of bash. The blocklist is a text file. Total infrastructure cost: zero — it runs on the developer's machine, calls an API we already pay for, adds 4 seconds to the commit flow.
+
+
The pre-commit hook is part of Tinqs Studio. The inference proxy, blocklist patterns, and review prompt are open and reusable. Every commit in Ariki runs through the same guard.
One Binary to Rule Them All: Our Studio CLI
- Every AI agent session starts the same way: cold. The agent doesn't know what project this is, who's asking, what tools are available, or what happened yesterday. You spend the first five minutes re-explaining context.
-
-Our CLI solves this in 100ms. One command — tinqs identity — and the agent knows everything. The binary is 15MB, has zero runtime dependencies, and runs on every machine in the studio.
-
-## The identity command (100ms)
-
-When an agent starts, the first thing it calls is tinqs identity. The output:
-
-- Soul file — the agent's persistent identity, values, operating principles
-- Company context — team members, roles, what the company does
-- Machine context — hostname, OS, which repos are cloned, what services are running
-- Ecosystem — other repos and their purpose
-- Service status — which URLs are live and reachable
-
-This data lives in markdown files in the docs repo. Any machine on the network can read it. The agent goes from blank to fully contextual in under a second.
-
-This started as a convenience tool for humans. It became the single most important function in our stack. Every agent session — Cursor, Claude Code, Pi — starts with tinqs identity. Without it, every conversation begins with "let me explain the project." With it, the agent already knows.
-
-## Screenshots and cloud vision
-
-The CLI can capture any window from outside the process. No in-game overlay, no rendering pipeline integration. OS-level capture — GDI+ on Windows, screencapture on Mac.
-
-A photo command sends the screenshot to a cloud vision model. The agent says "take a photo of the game" and gets back: "The player character is standing near a half-built hut. Three palm trees to the left. The terrain has a visible seam between two biomes."
-
-This is how you file bugs without typing. Look at the game, tell the agent what's wrong. It takes a screenshot, describes what it sees, and creates an issue with both the description and the image attached. Keyboard-free bug reporting.
-
-## Health checks
-
-tinqs doctor runs a comprehensive check:
-
-- Is the git platform reachable and authenticated?
-- Is the game server running?
-- Are all expected repos cloned and on the right branch?
-- Are required tools installed at the right version?
-
-Output is a green/yellow/red table. Essential for unattended agent sessions — the agent verifies its environment before starting work. No "the build failed because port 3000 was already taken" at 3am.
-
-## Why Go
-
-Go compiles to a single static binary. No Python virtualenvs, no Node.js version managers, no DLL hell on Windows. The same binary runs on a gaming PC, a designer's MacBook, and a CI runner in AWS.
-
-Cross-compilation is trivial. We build Windows, Mac (arm64 + amd64), and Linux binaries from a single CI workflow. Push a tag, CI builds all three, uploads to S3. The binary is 15MB, starts in under 100ms, has zero runtime dependencies.
-
-## What we learned
-
-The CLI is the API for AI agents. What started as a human convenience tool became the primary interface for agents. Every session starts with tinqs identity. The agent's "hands and eyes" — screenshots, vision, health checks — are subcommands of the same binary.
-
-One binary beats ten scripts. Scripts rot. They have different shells, different PATH assumptions, different error handling. A compiled binary either works or it doesn't. It ships with dependencies baked in. It doesn't care if your Python is 3.9 or 3.12.
-
-Cloud vision is underrated for game dev. Sending a screenshot to a vision model sounds gimmicky. In practice, it's the fastest way to document visual bugs. "The tree is floating 2m above the terrain" is much faster to communicate when the AI is looking at the same screen.
-
-Agent cold starts are the real problem. Without the identity system, every session starts with the agent asking "what project is this?" With it, the agent knows everything in 100ms. That's the difference between an AI assistant and an AI team member.
-
-—
-
-The CLI is part of Tinqs Studio. Every time we find ourselves about to write a script that needs to work on multiple machines, we add a subcommand instead. One binary that makes the studio work — whether the operator is human or AI.
+ Every AI agent session starts the same way: cold. The agent doesn't know what project this is, who's asking, what tools are available, or what happened yesterday. You spend the first five minutes re-explaining context.
+
Our CLI solves this in 100ms. One command — tinqs identity — and the agent knows everything. The binary is 15MB, has zero runtime dependencies, and runs on every machine in the studio.
+
The identity command (100ms)
+
When an agent starts, the first thing it calls is tinqs identity. The output:
+
+ - Soul file — the agent's persistent identity, values, operating principles
+ - Company context — team members, roles, what the company does
+ - Machine context — hostname, OS, which repos are cloned, what services are running
+ - Ecosystem — other repos and their purpose
+ - Service status — which URLs are live and reachable
+
+
This data lives in markdown files in the docs repo. Any machine on the network can read it. The agent goes from blank to fully contextual in under a second.
+
This started as a convenience tool for humans. It became the single most important function in our stack. Every agent session — Cursor, Claude Code, Pi — starts with tinqs identity. Without it, every conversation begins with "let me explain the project." With it, the agent already knows.
+
Screenshots and cloud vision
+
The CLI can capture any window from outside the process. No in-game overlay, no rendering pipeline integration. OS-level capture — GDI+ on Windows, screencapture on Mac.
+
A photo command sends the screenshot to a cloud vision model. The agent says "take a photo of the game" and gets back: "The player character is standing near a half-built hut. Three palm trees to the left. The terrain has a visible seam between two biomes."
+
This is how you file bugs without typing. Look at the game, tell the agent what's wrong. It takes a screenshot, describes what it sees, and creates an issue with both the description and the image attached. Keyboard-free bug reporting.
+
Health checks
+
tinqs doctor runs a comprehensive check:
+
+ - Is the git platform reachable and authenticated?
+ - Is the game server running?
+ - Are all expected repos cloned and on the right branch?
+ - Are required tools installed at the right version?
+
+
Output is a green/yellow/red table. Essential for unattended agent sessions — the agent verifies its environment before starting work. No "the build failed because port 3000 was already taken" at 3am.
+
Why Go
+
Go compiles to a single static binary. No Python virtualenvs, no Node.js version managers, no DLL hell on Windows. The same binary runs on a gaming PC, a designer's MacBook, and a CI runner in AWS.
+
Cross-compilation is trivial. We build Windows, Mac (arm64 + amd64), and Linux binaries from a single CI workflow. Push a tag, CI builds all three, uploads to S3. The binary is 15MB, starts in under 100ms, has zero runtime dependencies.
+
What we learned
+
The CLI is the API for AI agents. What started as a human convenience tool became the primary interface for agents. Every session starts with tinqs identity. The agent's "hands and eyes" — screenshots, vision, health checks — are subcommands of the same binary.
+
One binary beats ten scripts. Scripts rot. They have different shells, different PATH assumptions, different error handling. A compiled binary either works or it doesn't. It ships with dependencies baked in. It doesn't care if your Python is 3.9 or 3.12.
+
Cloud vision is underrated for game dev. Sending a screenshot to a vision model sounds gimmicky. In practice, it's the fastest way to document visual bugs. "The tree is floating 2m above the terrain" is much faster to communicate when the AI is looking at the same screen.
+
Agent cold starts are the real problem. Without the identity system, every session starts with the agent asking "what project is this?" With it, the agent knows everything in 100ms. That's the difference between an AI assistant and an AI team member.
+
+
The CLI is part of Tinqs Studio. Every time we find ourselves about to write a script that needs to work on multiple machines, we add a subcommand instead. One binary that makes the studio work — whether the operator is human or AI.
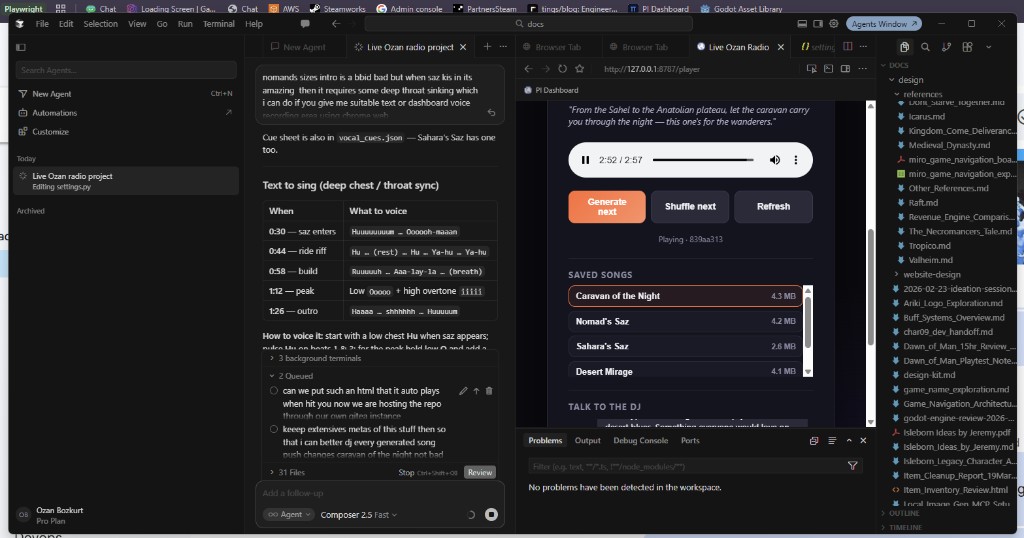
Why Voice Is the Missing Input for Game Development
- Every game developer knows this moment. You're playtesting, running through the world, and you see something wrong — a tree floating two meters above the terrain, a UI element clipping, an animation that stutters on frame 14. You make a mental note. Ten minutes later, back at the editor, you try to file it. The coordinates are fuzzy. The exact reproduction steps are gone. You type something vague like "tree floating on west beach maybe" and hope you remember more tomorrow.
+
Every game developer knows this moment. You're playtesting, running through the world, and you see something wrong — a tree floating two meters above the terrain, a UI element clipping, an animation that stutters on frame 14. You make a mental note. Ten minutes later, back at the editor, you try to file it. The coordinates are fuzzy. The exact reproduction steps are gone. You type something vague like "tree floating on west beach maybe" and hope you remember more tomorrow.
-Voice changes this entirely. Speak the bug while you're looking at it, and an agent turns your words into a structured issue — with a screenshot, a vision-model description, coordinates, and a severity estimate. No keyboard. No context switch. No memory loss.
-
-## The latency that kills bug reports
-
-The distance between seeing a bug and filing it is a memory decay curve. Every second that passes, your recollection loses precision:
-
-| Elapsed time | What you remember |
-|—|—|
-| 0 seconds | Exact position, camera angle, what you were doing, what's on screen |
-| 30 seconds | "There was a tree... somewhere west... maybe floating?" |
-| 5 minutes | "I think there was a rendering issue? Or was it yesterday?" |
-
-Typed bug reports are reconstructions from decaying memory. Voice bug reports are real-time captures. The difference in quality isn't marginal — it's the difference between a fix you can act on immediately and a ticket that sits in the backlog for three months while someone tries to reproduce it.
-
-## The pipeline: voice → text → structured issue
-
-Here's what actually happens when you speak a bug during playtesting:
-
-``
-1. You speak: "There's a tree floating two meters above the terrain
+
+
Voice changes this entirely. Speak the bug while you're looking at it, and an agent turns your words into a structured issue — with a screenshot, a vision-model description, coordinates, and a severity estimate. No keyboard. No context switch. No memory loss.
+
The latency that kills bug reports
+
The distance between seeing a bug and filing it is a memory decay curve. Every second that passes, your recollection loses precision:
+
| Elapsed time | What you remember |
+
|—|—|
+
| 0 seconds | Exact position, camera angle, what you were doing, what's on screen |
+
| 30 seconds | "There was a tree... somewhere west... maybe floating?" |
+
| 5 minutes | "I think there was a rendering issue? Or was it yesterday?" |
+
Typed bug reports are reconstructions from decaying memory. Voice bug reports are real-time captures. The difference in quality isn't marginal — it's the difference between a fix you can act on immediately and a ticket that sits in the backlog for three months while someone tries to reproduce it.
+
The pipeline: voice → text → structured issue
+
Here's what actually happens when you speak a bug during playtesting:
+
1. You speak: "There's a tree floating two meters above the terrain
on the west beach, near the big rock formation. Happens after
the vegetation culling pass kicks in around sunset."
@@ -316,68 +309,39 @@ Here's what actually happens when you speak a bug during playtesting:
5. Agent files a structured issue with all of the above,
tags the rendering engineer, and posts the digest to team chat.
-Total latency: under 2 seconds. You keep playing.
-``
-
-This isn't theoretical. The pipeline runs on our own game project, and it's caught bugs that would have slipped through playtesting entirely — the ones you see, make a mental note about, and forget by the time you alt-tab.
-
-## Why game dev is the perfect voice use case
-
-You're already looking at the screen. Voice input doesn't require switching windows or breaking flow. You're playtesting — your hands are on the controller or WASD, your eyes are on the game. Speaking is the only input channel that doesn't interrupt the thing you're actually doing.
-
-Game bugs are spatial and visual. "The crafting UI text overflows on items with names longer than 20 characters" is something you see, not something you calculate. Describing it verbally while looking at it produces a far richer bug report than typing from memory.
-
-Reproduction is half the battle. When you speak the bug at the moment of occurrence, you naturally include the context: what you were doing, what just happened, what the game state was. You don't have to reconstruct it later.
-
-Voice scales to the whole team. Artists see visual bugs. Designers see balance issues. Producers see UX friction. Not everyone on a game team is a fast typist or comfortable with issue trackers. Everyone can speak.
-
-## What the agent adds beyond transcription
-
-Raw transcription is useful — it's a notepad you don't have to type. But the agent layer is what makes voice input a pipeline rather than a dictation tool:
-
-Screenshot coordination. The agent calls the game engine's HTTP API, captures the current frame, and attaches it to the issue. You don't take screenshots. The agent does.
-
-Vision model description. The screenshot goes through a vision model that writes a text description of what's on screen. Future-you searching the issue tracker for "floating tree" finds it even if the transcription was garbled.
-
-Coordinates and context. The game engine provides the player's world position, camera angle, and current game state. The agent bakes these into the issue. A developer can teleport directly to the bug location.
-
-Severity and routing. The agent estimates severity from context ("floating" is visual, "crash" is critical) and tags the right team member. An artist doesn't get pinged for a shader bug. A rendering engineer doesn't get pinged for a UI text overflow.
-
-## The numbers
-
-| Method | Time from observation to filed issue | Information loss |
-|—|—|—|
-| Mental note → type later | 5-30 minutes | High (positions, steps, context) |
-| Alt-tab → type immediately | 30-60 seconds | Medium (screenshots missed, flow broken) |
-| Voice → agent pipeline | 2 seconds | Low (screenshot + position captured automatically) |
-
-The throughput difference compounds. A 30-minute playtest session with keyboard-only bug filing might yield 3-4 issues, half of them vague. The same session with voice-to-agent produces 10-15 issues, all with screenshots, positions, and reproduction context.
-
-## Setup is simpler than you think
-
-You need three things, all of which you probably already have:
-
-1. A microphone. The one in your headset is fine. Transcription models handle suboptimal audio surprisingly well.
-2. Transcription. Whisper runs locally and is free. Cloud APIs are sub-cent per minute. Both work.
-3. An agent that speaks your game engine's API. If your engine has an HTTP interface for screenshots and game state, the agent can wire the rest together. If it doesn't — add one. It's a weekend project.
-
-The agent itself doesn't need to be custom-built. Any coding agent with tool access can be told "watch the game, transcribe voice input, file issues in the tracker." It's a skill file, not a product.
-
-## What changes when you stop typing bugs
-
-The most surprising effect isn't the speed. It's the coverage. When filing a bug costs two seconds of speaking, you file bugs you would have previously ignored. The minor visual glitch. The slight animation hitch. The UI element that's two pixels misaligned.
-
-Individually these are low-priority. Collectively they're the difference between a game that feels polished and one that feels rough. And they only get caught when the cost of reporting approaches zero.
-
-The second effect is that playtesting becomes a primary input channel. Instead of structured QA sessions with checklists and forms, you just play the game. The agent captures everything. When you're done, you have a list of filed issues with screenshots and context — generated from your spoken observations in real time.
-
-Voice isn't a gimmick for game development. It's the input channel that matches the way we actually work — looking at the screen, noticing things, and talking about them. The tools exist. The latency is sub-second. The cost is negligible. The only thing missing is the habit.
-
-—
-
-We build Tinqs Studio — a game dev platform with built-in AI agents, git hosting, and creative pipelines. Ariki is the survival colony sim we're building with every tool described here.
-
-
+Total latency: under 2 seconds. You keep playing.
+
This isn't theoretical. The pipeline runs on our own game project, and it's caught bugs that would have slipped through playtesting entirely — the ones you see, make a mental note about, and forget by the time you alt-tab.
+
Why game dev is the perfect voice use case
+
You're already looking at the screen. Voice input doesn't require switching windows or breaking flow. You're playtesting — your hands are on the controller or WASD, your eyes are on the game. Speaking is the only input channel that doesn't interrupt the thing you're actually doing.
+
Game bugs are spatial and visual. "The crafting UI text overflows on items with names longer than 20 characters" is something you see, not something you calculate. Describing it verbally while looking at it produces a far richer bug report than typing from memory.
+
Reproduction is half the battle. When you speak the bug at the moment of occurrence, you naturally include the context: what you were doing, what just happened, what the game state was. You don't have to reconstruct it later.
+
Voice scales to the whole team. Artists see visual bugs. Designers see balance issues. Producers see UX friction. Not everyone on a game team is a fast typist or comfortable with issue trackers. Everyone can speak.
+
What the agent adds beyond transcription
+
Raw transcription is useful — it's a notepad you don't have to type. But the agent layer is what makes voice input a pipeline rather than a dictation tool:
+
Screenshot coordination. The agent calls the game engine's HTTP API, captures the current frame, and attaches it to the issue. You don't take screenshots. The agent does.
+
Vision model description. The screenshot goes through a vision model that writes a text description of what's on screen. Future-you searching the issue tracker for "floating tree" finds it even if the transcription was garbled.
+
Coordinates and context. The game engine provides the player's world position, camera angle, and current game state. The agent bakes these into the issue. A developer can teleport directly to the bug location.
+
Severity and routing. The agent estimates severity from context ("floating" is visual, "crash" is critical) and tags the right team member. An artist doesn't get pinged for a shader bug. A rendering engineer doesn't get pinged for a UI text overflow.
+
The numbers
+
| Method | Time from observation to filed issue | Information loss |
+
|—|—|—|
+
| Mental note → type later | 5-30 minutes | High (positions, steps, context) |
+
| Alt-tab → type immediately | 30-60 seconds | Medium (screenshots missed, flow broken) |
+
| Voice → agent pipeline | 2 seconds | Low (screenshot + position captured automatically) |
+
The throughput difference compounds. A 30-minute playtest session with keyboard-only bug filing might yield 3-4 issues, half of them vague. The same session with voice-to-agent produces 10-15 issues, all with screenshots, positions, and reproduction context.
+
Setup is simpler than you think
+
You need three things, all of which you probably already have:
+
1. A microphone. The one in your headset is fine. Transcription models handle suboptimal audio surprisingly well.
+
2. Transcription. Whisper runs locally and is free. Cloud APIs are sub-cent per minute. Both work.
+
3. An agent that speaks your game engine's API. If your engine has an HTTP interface for screenshots and game state, the agent can wire the rest together. If it doesn't — add one. It's a weekend project.
+
The agent itself doesn't need to be custom-built. Any coding agent with tool access can be told "watch the game, transcribe voice input, file issues in the tracker." It's a skill file, not a product.
+
What changes when you stop typing bugs
+
The most surprising effect isn't the speed. It's the coverage. When filing a bug costs two seconds of speaking, you file bugs you would have previously ignored. The minor visual glitch. The slight animation hitch. The UI element that's two pixels misaligned.
+
Individually these are low-priority. Collectively they're the difference between a game that feels polished and one that feels rough. And they only get caught when the cost of reporting approaches zero.
+
The second effect is that playtesting becomes a primary input channel. Instead of structured QA sessions with checklists and forms, you just play the game. The agent captures everything. When you're done, you have a list of filed issues with screenshots and context — generated from your spoken observations in real time.
+
Voice isn't a gimmick for game development. It's the input channel that matches the way we actually work — looking at the screen, noticing things, and talking about them. The tools exist. The latency is sub-second. The cost is negligible. The only thing missing is the habit.
+
+
We build Tinqs Studio — a game dev platform with built-in AI agents, git hosting, and creative pipelines. Ariki is the survival colony sim we're building with every tool described here.
 +
+