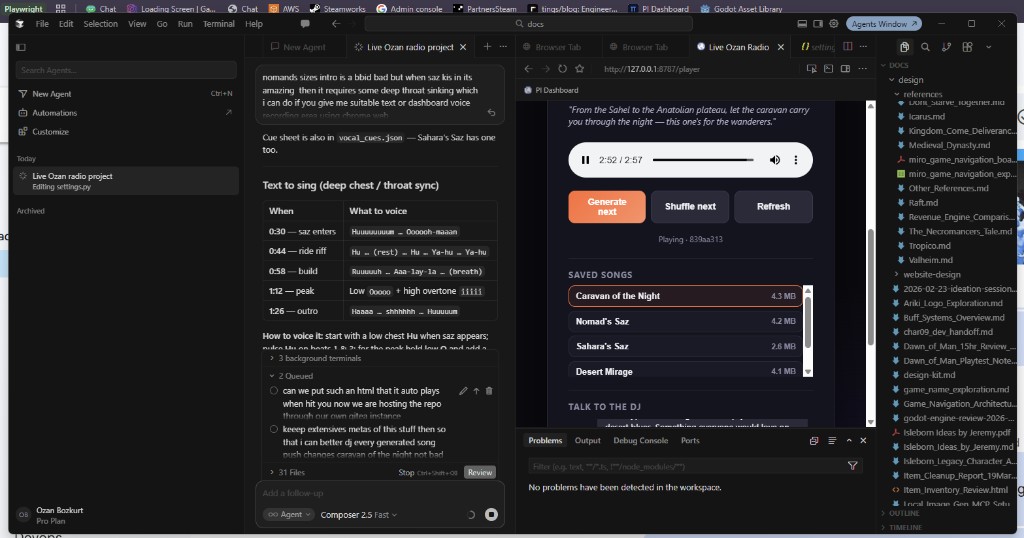
I do not want a playlist. I want a station — something that feels like late-night desert dub and Anadolu psych drifting out of a speaker, but every track is composed fresh, never pulled from Spotify or Apple Music. So we built Live Ozan Radio: DeepSeek as the on-air DJ, Google Lyria 3 as the music engine, and our own Gitea instance as the host.
-!Live Ozan Radio in Cursor — player dashboard, saved songs, and DJ chat beside the editor
+!Live Ozan Radio in Cursor — player dashboard, saved songs, and DJ chat beside the editor
That screenshot is how I actually use it: Cursor on the left with taste notes and vocal cues, the local player on :8787 on the right, saved songs in a scrollable library, and a chat box to steer the next generation. It is dogfooding in the truest sense — we run our game studio on the same Gitea fork we sell as Tinqs Studio, and the radio lives in that repo too.
diff --git a/posts/flows-are-sessions.md b/posts/flows-are-sessions.md
new file mode 100644
index 0000000..b459f46
--- /dev/null
+++ b/posts/flows-are-sessions.md
@@ -0,0 +1,133 @@
+---
+title: "Flows Are Sessions, Not Pipelines: Why We Moved Our Agent Orchestrator from YAML to JavaScript"
+slug: flows-are-sessions
+date: "2026-06-11"
+description: "We killed the static YAML DAG and rewrote our agent orchestration in 200 lines of JavaScript. Now a flow IS a session — you chat it, steer it, and it pauses for you at a human gate."
+og_description: "YAML DAGs are dead. We rewrote our agent orchestration in JavaScript, made every flow a live session, and added a human-in-the-loop gate. The operator is the co-pilot, not the babysitter."
+og_image: "https://www.tinqs.com/img/og-cover.jpg"
+excerpt: "We killed the static YAML DAG and rewrote our agent orchestration in 200 lines of JavaScript. Now a flow IS a session — you chat it, steer it, and it pauses for you at a human gate."
+author: "Ozan Bozkurt"
+author_initials: "OB"
+author_role: "CTO & Developer, Tinqs"
+---
+
+Our YAML flow engine had seven bespoke node types just to fake a `while` loop. We threw it out and rewrote everything in 200 lines of JavaScript. The flow engine is gone. The flow IS the session. Here's what we learned.
+
+## The YAML Was a Compiler for a Language Nobody Wanted
+
+The old system was a static DAG. You defined nodes and edges in YAML, the engine walked them top-to-bottom, and when it finished it was done. No mid-run interaction. No branching. No retry. If you wanted a loop, you didn't use a `while` statement — you used an `agent-loop-decision` node type. In YAML.
+
+```yaml
+# The old way: a "loop" was a bespoke node type
+steps:
+ - agent-task: "generate document"
+ - agent-loop-decision:
+ condition: "check if quality > 0.8"
+ if-true: "continue"
+ if-false: "repeat-step: agent-task"
+```
+
+That's not configuration. That's a compiler for a language nobody wanted to write. Every orchestrator ends up here — GitHub Actions expressions, GitLab CI `rules`, Airflow's `BranchPythonOperator`, all of them start as "simple YAML config" and grow node types until they're Turing-complete nightmares held together by schema patches.
+
+We had seven: `agent-task`, `agent-loop-decision`, `fork`, `conditional`, `agent-join`, `pipeline-stage`, `human-review`. Each one existed because YAML can't express control flow. You weren't writing a flow. You were filing paperwork to describe a flow.
+
+The moment we knew it was wrong: someone asked "can I retry this step three times if it fails?" and the honest answer was "we'd need a new node type." When your config format needs an RFC to add a `for` loop, you've built a programming language by accident. Delete it.
+
+## 200 Lines of JavaScript Replaced Seven Node Types
+
+A flow is now an ES module. You export `default async (flow) => {}` and the runtime calls it. The API surface is five calls:
+
+- `agent(prompt, options)` — run one agent with a task
+- `parallel(thunks)` — run many agents concurrently, await all
+- `pipeline(items, ...stages)` — push items through stages
+- `phase(name)` — label progress for the dashboard
+- `human(config)` — pause and wait for a person
+
+Here's a real flow. It reviews a code route change with parallel researchers and a human gate. Ten lines.
+
+```js
+// .pi/flows/flows/review-routes.flow.mjs
+export const meta = { name: "review-routes", description: "audit routes for missing auth" };
+export default async (flow) => {
+ const { agent, parallel, phase, human, task } = flow;
+ phase("find");
+ const findings = await parallel(["auth", "input"].map((d) => () =>
+ agent(`Review ${d}: ${task}`, { agent: "researcher", model: "@planning" })
+ ));
+ phase("review");
+ const gate = await human({ title: "Eyeball it", prompt: "anything to fix before I finish?" });
+ return { findings, gate };
+};
+```
+
+Why JavaScript wins is boring and fundamental: it has `while`, `if`, `try/catch`, and `parallel(thunks)` built in. The things our YAML needed custom schema types to fake are just language keywords. Bounded concurrency is a one-liner. Error recovery is a `try` block. A loop is `while (!approved)`. No plugin, no RFC, no new node type.
+
+We migrated all flows YAML-to-JS on 2026-06-10. One-way conversion script, every flow reviewed and running in 24 hours. The YAML parser was deleted — not deprecated, not kept for backwards compatibility, deleted. There's no config path left to reach for.
+
+The plan lives in code, not config. Config is for things that don't change. Agent orchestration changes every run.
+
+## A Flow IS a Session
+
+The old model had a phantom problem. A flow was a card. A session was a separate card. The operator watched the flow run from a different window. There was a "New Flow" button that created a flow card, and a "Continue" button that attached a session to it, and the disconnect between "the thing running your work" and "the place you talk to it" was baked into the UI.
+
+We killed that architecture. Every spawn is a session.
+
+When you call `POST /api/flows/spawn {cwd, task, flowName}`, the session runs the flow inside itself with the `flow_run` tool. Steps stream inline into the chat — `flow:steps` injects progress into the session's own message stream. The session turns purple in the dashboard. It becomes the flow. One card. One identity. Persistent after the run finishes.
+
+No "New Flow" button. No "Continue" button. You spawn a session; with a `flowName` it runs that flow, without one it opens an interactive operator session that designs a flow with you first. The dashboard branding is tinqs Studio. The control surface is the host card, live agent cards, run history, and a chat to steer the run.
+
+There's no phantom card. No disconnect between "the thing running your work" and "the place you talk to it." It's one session. You're in the room.
+
+## The Human Gate: Pause, Take Over, Approve, Continue
+
+Agents make mistakes. They guess when they shouldn't. They take irreversible actions because the prompt said "proceed." The model gets stuck and you sit there wondering — do I wait or abort?
+
+`flow.human()` is our answer.
+
+When a flow hits a human gate, it stops. The dashboard shows the gate prompt: what to review, what to decide. The host session switches to takeover mode — coding tools are unblocked (normally the host is hands-off) and the system prompt becomes "flow is paused, help the operator finish this." You open files. You edit. You verify. You run commands.
+
+To release the gate, reply `approve` or `done` or `lgtm`. The flow resumes. Any other message is a work instruction — the takeover session executes it but does not release the gate. The flow loops on `notes` until the human says go.
+
+```js
+let approved = false;
+while (!approved) {
+ const { notes } = await human({
+ title: "Review before push",
+ prompt: "Check the diff. Approve or tell me what to fix.",
+ });
+ if (notes.match(/^(approve|done|lgtm|looks good)/i)) approved = true;
+ else await agent(`Fix: ${notes}`, { agent: "implementer" });
+}
+```
+
+Two patterns this enables. First: review-approve-before-push gates — nobody ships untested code because nobody set the `auto-approve` flag to true. Second: the "agent is stuck" hand-off — the flow pauses, you take over the exact same workspace, fix the problem, type `continue`, and the flow keeps going.
+
+The flow waits instead of guessing. This isn't a feature. It's an admission that some decisions shouldn't be automated.
+
+## The Operator Is Your Co-Pilot
+
+The old way was a one-shot generator. Paste an objective, click Generate, get a YAML blob, pray it's right, run it, discover it's wrong 20 minutes in with no way to steer. We'd watch flows fail and think "I could have told it that before it started."
+
+The new flow operator doesn't write the flow for you and walk away. It designs it with you.
+
+Hit New Flow. A DeepSeek session opens — the same model that powers the dashboard, cheap at $0.28/MTok, steerable in natural language. It proposes a draft `.flow.mjs`, shows you the agents and phases and any human gate, and explains why. You tell it what to change. It does NOT launch until you say go. When you approve, it writes the flow file and spawns a separate host session, then attaches to monitor and report progress.
+
+The operator is still in the chat when the human gate fires. It's still there when you want to change the plan mid-run. It doesn't go away after launch. Co-pilot, not autopilot.
+
+There are three runner faces for the same engine: **pi/dashboard** (DeepSeek, cheap, steerable — the default), **Claude Code** (Workflow tool, one-shot fan-out for heavy research), and a **cloud agent** (remote deploy, clone, AWS). Pick by granularity and cost. The flow file is the same in all three modes.
+
+## What We Learned
+
+**Numbers first.** 43 out of 43 unit tests green. All flows migrated. The supervisor inbox — steering messages sent between steps — was silently dropping operator messages before 2026-06-10. You'd type "focus on the auth routes" and the flow never saw it. That's fixed now. Chat reaches the inbox, the inbox drains between `agent()` calls, and steering works.
+
+**The inbox rule.** The supervisor inbox is applied between `agent()` calls, never mid-step. Steering mid-step is undefined behaviour. We learned this the hard way — early versions tried to inject mid-agent and got corrupted state, partial outputs, agents that forgot what they were doing. Between steps is the right boundary. Respect it.
+
+**Economics matter.** DeepSeek V4 Pro at $0.28/MTok runs per-step. Per-step model override lets you swap in a premium reasoning model ($15/MTok) for the one critical call that needs it. $0.28 for routine, $15 for the hard parts. The three-tier strategy from our agent daemon applies at flow granularity too.
+
+**What's next.** Richer on-card flow display — a pinned step strip so you can see progress without opening the session. Attachable asset and agent-structure viewers in the flow card. Run replay for finished sessions after a page reload (the session persists, but you can't rewatch the stream yet).
+
+But the principle is settled. A flow isn't a pipeline. A pipeline runs blind and reports back later. A flow is a pair-programming session where one of the pair happens to be code.
+
+---
+
+*[Tinqs Studio](https://tinqs.com) is our agent-native development platform — git hosting, AI agents, and the flow engine described here. [Ariki](https://arikigame.com) is the survival colony sim we're building with it.*
diff --git a/posts/gpu-skinned-herds.md b/posts/gpu-skinned-herds.md
new file mode 100644
index 0000000..a1b3a28
--- /dev/null
+++ b/posts/gpu-skinned-herds.md
@@ -0,0 +1,112 @@
+---
+title: "GPU-Skinned Herds: One Draw Call for 1,000 Animated Characters in Godot"
+slug: gpu-skinned-herds
+date: "2026-06-14"
+description: "Godot has no built-in way to render 1,000 skinned characters in one draw call. We built a GPU skinned-instance renderer into Tinqs Engine that does — 25 crocodiles verified, 1,000+ projected. Pre-built binaries for macOS and Windows."
+og_description: "One draw call, 1,000 animated characters. GPU-skinned herd renderer built into the Tinqs Engine fork of Godot."
+og_image: "https://www.tinqs.com/img/og-cover.jpg"
+excerpt: "Godot can't batch-render 1,000 animated characters. We built a GPU skinned-instance herd renderer into the engine itself — already driving crocodile herds in Ariki. Pre-built editor binaries for macOS and Windows."
+author: "Ozan Bozkurt"
+author_initials: "OB"
+author_role: "CTO & Developer, Tinqs"
+---
+Godot gives you one `Skeleton3D` per character. Want 200 animals in a herd? That's 200 skeleton nodes, 200 draw calls, and 200 `AnimationPlayer` ticks every frame. Want 1,000? Now you're measuring in seconds per frame, not frames per second.
+
+We built a GPU skinned-instance renderer into Tinqs Engine that packs every pose into a single texture, uploads once, and draws every instance in one call. 25 crocodiles on screen right now. 1,000+ projected. Same bone count, same animation fidelity — a tiny fraction of the cost.
+
+## Why the engine needs to change
+
+The standard Godot approach — one `Skeleton3D` + one `MeshInstance3D` per character — works for a handful of animated entities. It breaks down hard at crowd scale:
+
+- **CPU bone transforms.** Computing `global_pose` for 200 skeletons × 100 bones each = 20,000 matrix multiplies per frame, all on the main thread.
+- **Draw call explosion.** Each `MeshInstance3D` is its own draw call. Even with MultiMesh, there's no built-in path for skinned meshes — `MultiMeshInstance3D` only handles static geometry.
+- **AnimationPlayer sprawl.** Each skeleton needs its own `AnimationPlayer` and its own `process()` tick.
+
+The alternative — baking animations to vertex textures — works for static crowds but locks you out of per-instance variation. No blending, no phase offsets, no reactive behaviour.
+
+What we need is simpler: **share the skeleton, drive per-instance poses from a single animation, batch the draw call.** That's what `agent_skinned` does.
+
+## How it works: two classes, one texture
+
+The module lives in `modules/agent_skinned/` inside [Tinqs Engine](https://tinqs.com/tinqs/engine). Two classes, one job:
+
+### `MultiSkinnedMeshInstance3D` — the data plane
+
+Holds the CPU-side bone matrices. Allocates an `ImageTexture` of size `[4 × max_bones, max_instances]` in RGBA32F — each texel is one column of a 4×4 bone matrix. For a 130-bone crocodile with 256 instances:
+
+```
+Texture: 520 × 256 RGBA32F ≈ 2 MB
+```
+
+That's the entire pose state for 256 animated crocodiles in a single GPU texture. The API is simple:
+
+```gdscript
+var data := MultiSkinnedMeshInstance3D.new()
+data.set_mesh(crocodile_mesh)
+data.set_skeleton(skeleton) # rest pose + bone hierarchy
+data.set_max_instances(256)
+data.set_max_bones(130)
+
+# Each frame: push poses from the animated skeleton
+for instance in herd_positions:
+ data.set_instance_pose_bones(instance.id, bone_transforms)
+data.update() # upload only dirty instances, not the whole texture
+```
+
+### `MultiSkinnedInstance3D` — the renderer
+
+A `MultiMeshInstance3D` subclass. Set its multimesh with the skinned mesh and instance transforms, point it at the data plane, call `refresh()` — it uploads the bone texture into the shader material's `bone_matrices_tex` uniform and the mesh is drawn in one call.
+
+The shader does 4-bone linear-blend skinning on the GPU:
+
+```glsl
+mat4 get_bone(int b) {
+ return mat4(
+ texelFetch(bone_matrices_tex, ivec2(b * 4 + 0, INSTANCE_ID), 0),
+ texelFetch(bone_matrices_tex, ivec2(b * 4 + 1, INSTANCE_ID), 0),
+ texelFetch(bone_matrices_tex, ivec2(b * 4 + 2, INSTANCE_ID), 0),
+ texelFetch(bone_matrices_tex, ivec2(b * 4 + 3, INSTANCE_ID), 0)
+ );
+}
+```
+
+`INSTANCE_ID` is a Godot built-in — the GPU already knows which instance it's rendering. We just use it to index into the bone texture. No uniform arrays, no SSBOs, no compute shaders. Just a 2D texture and a custom vertex shader.
+
+## Two bugs we shipped and fixed
+
+The module had data-plane doctests from day one — round-trip pose get/set, dirty tracking, size clamping, AABB. All green. Then we put it on screen for the first time and the crocodiles looked... wrong.
+
+**Bug 1: Shader compile failure.** The default skinning shader compared `TANGENT` as `vec4`. Godot 4 exposes it as `vec3`. Fixed in one line, added `albedo_tex` uniform so herds texture out of the box.
+
+**Bug 2: Bone matrices stored transposed.** The data plane wrote basis rows (standard Godot `Transform3D.basis` is row-major), but the shader unpacked as columns. Every bone matrix was transposed — the mesh crumpled. Not a scale bug, not an orientation bug — a layout mismatch. Fixed by storing column-major, with a doctest to prevent regression.
+
+The lesson: doctests catch logic. Rendering catches truth. You need both.
+
+## What's driving it
+
+In [Ariki](https://www.arikigame.com), the sim tracks animal migration across a 12km archipelago. `AnimalHerdRenderer.cs` groups sim `ViewerState.animals` by type, feeds positions to `skinned_herd.gd` (a reusable per-type herd backend), which drives the renderer. One `AnimationPlayer` animates a single driver skeleton; poses propagate to every instance.
+
+The crocodile herd scene is 25 instances, one draw call. The same pipeline projects to 200–1,000 before the GPU budget even notices.
+
+## What's deliberately not here
+
+- **No C# wrapper.** Instantiate from GDScript via `ClassDB.instantiate()` — the binding surface is small and stable.
+- **No automatic `AnimationPlayer` integration.** You drive poses. We give you the texture. Freedom to animate however you want.
+- **No GPU occlusion or LOD.** That's the game's job. The engine provides the tool; the game decides what to draw.
+
+## Get the build
+
+Pre-built editor binaries with `agent_skinned` baked in — no engine compile required:
+
+| Platform | Binary | Engine commit |
+|----------|--------|---------------|
+| **macOS ARM64** | [`tinqs.macos.editor.arm64.mono`](https://tinqs.com/tinqs/builds/media/branch/main/engine/macos-arm64/tinqs.macos.editor.arm64.mono) | `4fe1323` (4.6.4, Xcode 26.3) |
+| **Windows x64** | [`tinqs.windows.editor.x86_64.mono.exe`](https://tinqs.com/tinqs/builds/media/branch/main/engine/windows-x64/tinqs.windows.editor.x86_64.mono.exe) | `64fb5cc` (4.6.4, MSVC 2022) |
+
+All builds live in the public [`tinqs/builds`](https://tinqs.com/tinqs/builds) repo — engine source is private, but the binaries are yours. See [`manifest.json`](https://tinqs.com/tinqs/builds/src/branch/main/manifest.json) for checksums and build details.
+
+The engine source lives in [`tinqs/engine`](https://tinqs.com/tinqs/engine) (private). Module docs: `modules/agent_skinned/README.md` and `.agents/wiki/agent-skinned-gpu-herd.md`.
+
+---
+
+**Related:** [Fork, Don't Build](fork-dont-build) — why we modify existing platforms instead of building new ones. [Streaming a 12km Archipelago in Godot 4](godot-optimisation) — the terrain and vegetation streaming layers that work alongside this.
diff --git a/pre-commit-agent.html b/pre-commit-agent.html
index 7e23e4d..1144681 100644
--- a/pre-commit-agent.html
+++ b/pre-commit-agent.html
@@ -262,33 +262,45 @@
← All Posts
25 May 2026
-
A checklist in the README doesn't work. Humans skip checklists. Code review catches some issues but not all — reviewers focus on logic, not whether a URL points to a deleted org.
-
We built a pre-commit hook with two layers: a regex blocklist that's instant and free, and an LLM review that costs $0.001. Together they catch everything.
-
Layer 1: Regex blocklist (0ms, $0.00)
-
A text file of patterns, each tagged with scope and message:
-
public|\b<internal-codename>\b|Classified codename — use the public-facing alias
+A checklist in the README doesn't work. Humans skip checklists. Code review catches some issues but not all — reviewers focus on logic, not whether a URL points to a deleted org.
+
+We built a pre-commit hook with two layers: a regex blocklist that's instant and free, and an LLM review that costs $0.001. Together they catch everything.
+
+## Layer 1: Regex blocklist (0ms, $0.00)
+
+A text file of patterns, each tagged with scope and message:
+
+``
+public|\b\b|Classified codename — use the public-facing alias
all|github\.com/(tinqs-ltd|tinqs)/|GitHub repos deleted — use tinqs.com
all|sk-[a-zA-Z0-9]{20,}|Possible API key leaked
all|AKIA[A-Z0-9]{16}|AWS access key leaked
-public|admin\.<internal-domain>|Internal admin URL in public content
-
The scope field controls where patterns apply. all means every file. public means only public-facing content — blog posts, website, marketing pages. We want classified codenames in internal architecture docs. We just don't want them in blog posts.
-
The blocklist runs grep against the staged diff. No network call, no API, no latency. Match found → commit blocked immediately with file path and explanation. This catches 80% of issues before the LLM wakes up.
-
Layer 2: DeepSeek V4 Flash review (~4s, $0.001)
-
If the commit touches public-facing files, the hook sends the staged diff to DeepSeek V4 Flash. The system prompt tells it exactly what to check:
-
- - Leaked secrets — API keys, tokens, credentials the regex might have missed
- - Classified terms — codenames not yet in the blocklist
- - Internal URLs — references to services that shouldn't be public
- - Blog quality — title length, meta description, slug consistency
- - Broken links — malformed URLs, obvious typos
- - Announcements — if it's a new blog post, draft a one-line summary
-
-
The model responds with structured JSON: errors (block) or warnings (inform but allow). If the API is unreachable or times out, the commit proceeds — the hook never blocks work for infrastructure reasons.
-
The architecture
-
git commit
+public|admin\.|Internal admin URL in public content
+`
+
+The scope field controls where patterns apply. all means every file. public means only public-facing content — blog posts, website, marketing pages. We want classified codenames in internal architecture docs. We just don't want them in blog posts.
+
+The blocklist runs grep against the staged diff. No network call, no API, no latency. Match found → commit blocked immediately with file path and explanation. This catches 80% of issues before the LLM wakes up.
+
+## Layer 2: DeepSeek V4 Flash review (~4s, $0.001)
+
+If the commit touches public-facing files, the hook sends the staged diff to DeepSeek V4 Flash. The system prompt tells it exactly what to check:
+
+- Leaked secrets — API keys, tokens, credentials the regex might have missed
+- Classified terms — codenames not yet in the blocklist
+- Internal URLs — references to services that shouldn't be public
+- Blog quality — title length, meta description, slug consistency
+- Broken links — malformed URLs, obvious typos
+- Announcements — if it's a new blog post, draft a one-line summary
+
+The model responds with structured JSON: errors (block) or warnings (inform but allow). If the API is unreachable or times out, the commit proceeds — the hook never blocks work for infrastructure reasons.
+
+## The architecture
+
+`
+git commit
↓
Phase 0: Collect staged diff + classify files (public vs internal)
↓
@@ -304,33 +316,52 @@ Phase 3: Parse JSON response
→ Errors → BLOCK
→ Warnings → print, exit 0
→ Announcement → print draft
- → API failure → warn, exit 0 (never block on infra)
-
The hook lives in .githooks/ — committed, version-controlled, shared by the team. A setup script points git config core.hooksPath there.
-
What it costs
-
| | Tokens | Cost |
-
|–|——–|——|
-
| Input (prompt + diff) | ~4,000 | $0.00056 |
-
| Output (JSON response) | ~200 | $0.00006 |
-
| Per commit | | $0.00062 |
-
A tenth of a cent. Twenty commits a day: $0.012/day. About $0.40/month. Commits that only touch internal files skip the AI review entirely — zero cost.
-
What it caught (first week)
-
- - 2 classified codename leaks in draft blog posts — caught by blocklist
- - 1 GitHub URL from an old copy-paste — caught by blocklist
- - 3 blog SEO warnings — titles over 60 chars, missing og_description — caught by AI
- - 1 announcement draft auto-generated when a new post was committed
-
-
Zero false positives on the blocklist. Two false positives from the AI — flagged an internal URL in a code example that was clearly illustrative. We added a note to the prompt: ignore URLs inside fenced code blocks.
-
Setup
-
bash scripts/setup-hooks.sh # or .\scripts\setup-hooks.ps1 on Windows
-export TINQS_HOOK_TOKEN=<your-token> # same PAT used for git push
-
That's it. Every git commit runs the two-layer review. Bypass with git commit –no-verify for emergencies.
-
The pattern: guard rails at the edge
-
This is the same principle we apply everywhere: put the guard rail where the action happens. Don't rely on a human checklist. Don't wait for code review. Don't hope someone remembers.
-
The pre-commit hook is $0.001 of prevention. A leaked API key in a public post is hours of rotation, revocation, and audit. A classified codename in a blog post is a confidentiality breach. A dead link is a broken experience nobody notices for weeks.
-
The tools exist. DeepSeek V4 Flash is cheap enough to call on every commit. The hook is 150 lines of bash. The blocklist is a text file. Total infrastructure cost: zero — it runs on the developer's machine, calls an API we already pay for, adds 4 seconds to the commit flow.
-
-
The pre-commit hook is part of Tinqs Studio. The inference proxy, blocklist patterns, and review prompt are open and reusable. Every commit in Ariki runs through the same guard.
+ → API failure → warn, exit 0 (never block on infra)
+`
+
+The hook lives in .githooks/
— committed, version-controlled, shared by the team. A setup script points git config core.hooksPath
there.
+
+## What it costs
+
+| | Tokens | Cost |
+|–|——–|——|
+| Input (prompt + diff) | ~4,000 | $0.00056 |
+| Output (JSON response) | ~200 | $0.00006 |
+| Per commit | | $0.00062 |
+
+A tenth of a cent. Twenty commits a day: $0.012/day. About $0.40/month. Commits that only touch internal files skip the AI review entirely — zero cost.
+
+## What it caught (first week)
+
+- 2 classified codename leaks in draft blog posts — caught by blocklist
+- 1 GitHub URL from an old copy-paste — caught by blocklist
+- 3 blog SEO warnings — titles over 60 chars, missing og_description — caught by AI
+- 1 announcement draft auto-generated when a new post was committed
+
+Zero false positives on the blocklist. Two false positives from the AI — flagged an internal URL in a code example that was clearly illustrative. We added a note to the prompt: ignore URLs inside fenced code blocks.
+
+## Setup
+
+`
bash
+bash scripts/setup-hooks.sh # or .\scripts\setup-hooks.ps1 on Windows
+export TINQS_HOOK_TOKEN= # same PAT used for git push
+`
+
+That's it. Every git commit
runs the two-layer review. Bypass with git commit –no-verify` for emergencies.
+
+## The pattern: guard rails at the edge
+
+This is the same principle we apply everywhere: put the guard rail where the action happens. Don't rely on a human checklist. Don't wait for code review. Don't hope someone remembers.
+
+The pre-commit hook is $0.001 of prevention. A leaked API key in a public post is hours of rotation, revocation, and audit. A classified codename in a blog post is a confidentiality breach. A dead link is a broken experience nobody notices for weeks.
+
+The tools exist. DeepSeek V4 Flash is cheap enough to call on every commit. The hook is 150 lines of bash. The blocklist is a text file. Total infrastructure cost: zero — it runs on the developer's machine, calls an API we already pay for, adds 4 seconds to the commit flow.
+
+—
+
+
The pre-commit hook is part of Tinqs Studio. The inference proxy, blocklist patterns, and review prompt are open and reusable. Every commit in Ariki runs through the same guard.
+
+
diff --git a/screenshot-post.png b/screenshot-post.png
new file mode 100644
index 0000000..c0c6674
Binary files /dev/null and b/screenshot-post.png differ
diff --git a/studio-cli.html b/studio-cli.html
index 57a759b..9df3c08 100644
--- a/studio-cli.html
+++ b/studio-cli.html
@@ -262,44 +262,64 @@
← All Posts
18 May 2026
One Binary to Rule Them All: Our Studio CLI
-
Every AI agent session starts the same way: cold. The agent doesn't know what project this is, who's asking, what tools are available, or what happened yesterday. You spend the first five minutes re-explaining context.
+
Every AI agent session starts the same way: cold. The agent doesn't know what project this is, who's asking, what tools are available, or what happened yesterday. You spend the first five minutes re-explaining context.
+
+Our CLI solves this in 100ms. One command — tinqs identity — and the agent knows everything. The binary is 15MB, has zero runtime dependencies, and runs on every machine in the studio.
+
+## The identity command (100ms)
+
+When an agent starts, the first thing it calls is tinqs identity. The output:
+
+- Soul file — the agent's persistent identity, values, operating principles
+- Company context — team members, roles, what the company does
+- Machine context — hostname, OS, which repos are cloned, what services are running
+- Ecosystem — other repos and their purpose
+- Service status — which URLs are live and reachable
+
+This data lives in markdown files in the docs repo. Any machine on the network can read it. The agent goes from blank to fully contextual in under a second.
+
+This started as a convenience tool for humans. It became the single most important function in our stack. Every agent session — Cursor, Claude Code, Pi — starts with tinqs identity. Without it, every conversation begins with "let me explain the project." With it, the agent already knows.
+
+## Screenshots and cloud vision
+
+The CLI can capture any window from outside the process. No in-game overlay, no rendering pipeline integration. OS-level capture — GDI+ on Windows, screencapture on Mac.
+
+A photo command sends the screenshot to a cloud vision model. The agent says "take a photo of the game" and gets back: "The player character is standing near a half-built hut. Three palm trees to the left. The terrain has a visible seam between two biomes."
+
+This is how you file bugs without typing. Look at the game, tell the agent what's wrong. It takes a screenshot, describes what it sees, and creates an issue with both the description and the image attached. Keyboard-free bug reporting.
+
+## Health checks
+
+tinqs doctor runs a comprehensive check:
+
+- Is the git platform reachable and authenticated?
+- Is the game server running?
+- Are all expected repos cloned and on the right branch?
+- Are required tools installed at the right version?
+
+Output is a green/yellow/red table. Essential for unattended agent sessions — the agent verifies its environment before starting work. No "the build failed because port 3000 was already taken" at 3am.
+
+## Why Go
+
+Go compiles to a single static binary. No Python virtualenvs, no Node.js version managers, no DLL hell on Windows. The same binary runs on a gaming PC, a designer's MacBook, and a CI runner in AWS.
+
+Cross-compilation is trivial. We build Windows, Mac (arm64 + amd64), and Linux binaries from a single CI workflow. Push a tag, CI builds all three, uploads to S3. The binary is 15MB, starts in under 100ms, has zero runtime dependencies.
+
+## What we learned
+
+The CLI is the API for AI agents. What started as a human convenience tool became the primary interface for agents. Every session starts with tinqs identity. The agent's "hands and eyes" — screenshots, vision, health checks — are subcommands of the same binary.
+
+One binary beats ten scripts. Scripts rot. They have different shells, different PATH assumptions, different error handling. A compiled binary either works or it doesn't. It ships with dependencies baked in. It doesn't care if your Python is 3.9 or 3.12.
+
+Cloud vision is underrated for game dev. Sending a screenshot to a vision model sounds gimmicky. In practice, it's the fastest way to document visual bugs. "The tree is floating 2m above the terrain" is much faster to communicate when the AI is looking at the same screen.
+
+Agent cold starts are the real problem. Without the identity system, every session starts with the agent asking "what project is this?" With it, the agent knows everything in 100ms. That's the difference between an AI assistant and an AI team member.
+
+—
+
+The CLI is part of Tinqs Studio. Every time we find ourselves about to write a script that needs to work on multiple machines, we add a subcommand instead. One binary that makes the studio work — whether the operator is human or AI.
-
Our CLI solves this in 100ms. One command — tinqs identity — and the agent knows everything. The binary is 15MB, has zero runtime dependencies, and runs on every machine in the studio.
-
The identity command (100ms)
-
When an agent starts, the first thing it calls is tinqs identity. The output:
-
- - Soul file — the agent's persistent identity, values, operating principles
- - Company context — team members, roles, what the company does
- - Machine context — hostname, OS, which repos are cloned, what services are running
- - Ecosystem — other repos and their purpose
- - Service status — which URLs are live and reachable
-
-
This data lives in markdown files in the docs repo. Any machine on the network can read it. The agent goes from blank to fully contextual in under a second.
-
This started as a convenience tool for humans. It became the single most important function in our stack. Every agent session — Cursor, Claude Code, Pi — starts with tinqs identity. Without it, every conversation begins with "let me explain the project." With it, the agent already knows.
-
Screenshots and cloud vision
-
The CLI can capture any window from outside the process. No in-game overlay, no rendering pipeline integration. OS-level capture — GDI+ on Windows, screencapture on Mac.
-
A photo command sends the screenshot to a cloud vision model. The agent says "take a photo of the game" and gets back: "The player character is standing near a half-built hut. Three palm trees to the left. The terrain has a visible seam between two biomes."
-
This is how you file bugs without typing. Look at the game, tell the agent what's wrong. It takes a screenshot, describes what it sees, and creates an issue with both the description and the image attached. Keyboard-free bug reporting.
-
Health checks
-
tinqs doctor runs a comprehensive check:
-
- - Is the git platform reachable and authenticated?
- - Is the game server running?
- - Are all expected repos cloned and on the right branch?
- - Are required tools installed at the right version?
-
-
Output is a green/yellow/red table. Essential for unattended agent sessions — the agent verifies its environment before starting work. No "the build failed because port 3000 was already taken" at 3am.
-
Why Go
-
Go compiles to a single static binary. No Python virtualenvs, no Node.js version managers, no DLL hell on Windows. The same binary runs on a gaming PC, a designer's MacBook, and a CI runner in AWS.
-
Cross-compilation is trivial. We build Windows, Mac (arm64 + amd64), and Linux binaries from a single CI workflow. Push a tag, CI builds all three, uploads to S3. The binary is 15MB, starts in under 100ms, has zero runtime dependencies.
-
What we learned
-
The CLI is the API for AI agents. What started as a human convenience tool became the primary interface for agents. Every session starts with tinqs identity. The agent's "hands and eyes" — screenshots, vision, health checks — are subcommands of the same binary.
-
One binary beats ten scripts. Scripts rot. They have different shells, different PATH assumptions, different error handling. A compiled binary either works or it doesn't. It ships with dependencies baked in. It doesn't care if your Python is 3.9 or 3.12.
-
Cloud vision is underrated for game dev. Sending a screenshot to a vision model sounds gimmicky. In practice, it's the fastest way to document visual bugs. "The tree is floating 2m above the terrain" is much faster to communicate when the AI is looking at the same screen.
-
Agent cold starts are the real problem. Without the identity system, every session starts with the agent asking "what project is this?" With it, the agent knows everything in 100ms. That's the difference between an AI assistant and an AI team member.
-
-
The CLI is part of Tinqs Studio. Every time we find ourselves about to write a script that needs to work on multiple machines, we add a subcommand instead. One binary that makes the studio work — whether the operator is human or AI.
diff --git a/voice-missing-input-game-dev.html b/voice-missing-input-game-dev.html
index ee04629..52c0f9c 100644
--- a/voice-missing-input-game-dev.html
+++ b/voice-missing-input-game-dev.html
@@ -262,21 +262,28 @@
← All Posts
10 June 2026
Why Voice Is the Missing Input for Game Development
-
Every game developer knows this moment. You're playtesting, running through the world, and you see something wrong — a tree floating two meters above the terrain, a UI element clipping, an animation that stutters on frame 14. You make a mental note. Ten minutes later, back at the editor, you try to file it. The coordinates are fuzzy. The exact reproduction steps are gone. You type something vague like "tree floating on west beach maybe" and hope you remember more tomorrow.
+
Every game developer knows this moment. You're playtesting, running through the world, and you see something wrong — a tree floating two meters above the terrain, a UI element clipping, an animation that stutters on frame 14. You make a mental note. Ten minutes later, back at the editor, you try to file it. The coordinates are fuzzy. The exact reproduction steps are gone. You type something vague like "tree floating on west beach maybe" and hope you remember more tomorrow.
-
-
Voice changes this entirely. Speak the bug while you're looking at it, and an agent turns your words into a structured issue — with a screenshot, a vision-model description, coordinates, and a severity estimate. No keyboard. No context switch. No memory loss.
-
The latency that kills bug reports
-
The distance between seeing a bug and filing it is a memory decay curve. Every second that passes, your recollection loses precision:
-
| Elapsed time | What you remember |
-
|—|—|
-
| 0 seconds | Exact position, camera angle, what you were doing, what's on screen |
-
| 30 seconds | "There was a tree... somewhere west... maybe floating?" |
-
| 5 minutes | "I think there was a rendering issue? Or was it yesterday?" |
-
Typed bug reports are reconstructions from decaying memory. Voice bug reports are real-time captures. The difference in quality isn't marginal — it's the difference between a fix you can act on immediately and a ticket that sits in the backlog for three months while someone tries to reproduce it.
-
The pipeline: voice → text → structured issue
-
Here's what actually happens when you speak a bug during playtesting:
-
1. You speak: "There's a tree floating two meters above the terrain
+Voice changes this entirely. Speak the bug while you're looking at it, and an agent turns your words into a structured issue — with a screenshot, a vision-model description, coordinates, and a severity estimate. No keyboard. No context switch. No memory loss.
+
+## The latency that kills bug reports
+
+The distance between seeing a bug and filing it is a memory decay curve. Every second that passes, your recollection loses precision:
+
+| Elapsed time | What you remember |
+|—|—|
+| 0 seconds | Exact position, camera angle, what you were doing, what's on screen |
+| 30 seconds | "There was a tree... somewhere west... maybe floating?" |
+| 5 minutes | "I think there was a rendering issue? Or was it yesterday?" |
+
+Typed bug reports are reconstructions from decaying memory. Voice bug reports are real-time captures. The difference in quality isn't marginal — it's the difference between a fix you can act on immediately and a ticket that sits in the backlog for three months while someone tries to reproduce it.
+
+## The pipeline: voice → text → structured issue
+
+Here's what actually happens when you speak a bug during playtesting:
+
+``
+1. You speak: "There's a tree floating two meters above the terrain
on the west beach, near the big rock formation. Happens after
the vegetation culling pass kicks in around sunset."
@@ -294,39 +301,68 @@
5. Agent files a structured issue with all of the above,
tags the rendering engineer, and posts the digest to team chat.
-Total latency: under 2 seconds. You keep playing.
-
This isn't theoretical. The pipeline runs on our own game project, and it's caught bugs that would have slipped through playtesting entirely — the ones you see, make a mental note about, and forget by the time you alt-tab.
-
Why game dev is the perfect voice use case
-
You're already looking at the screen. Voice input doesn't require switching windows or breaking flow. You're playtesting — your hands are on the controller or WASD, your eyes are on the game. Speaking is the only input channel that doesn't interrupt the thing you're actually doing.
-
Game bugs are spatial and visual. "The crafting UI text overflows on items with names longer than 20 characters" is something you see, not something you calculate. Describing it verbally while looking at it produces a far richer bug report than typing from memory.
-
Reproduction is half the battle. When you speak the bug at the moment of occurrence, you naturally include the context: what you were doing, what just happened, what the game state was. You don't have to reconstruct it later.
-
Voice scales to the whole team. Artists see visual bugs. Designers see balance issues. Producers see UX friction. Not everyone on a game team is a fast typist or comfortable with issue trackers. Everyone can speak.
-
What the agent adds beyond transcription
-
Raw transcription is useful — it's a notepad you don't have to type. But the agent layer is what makes voice input a pipeline rather than a dictation tool:
-
Screenshot coordination. The agent calls the game engine's HTTP API, captures the current frame, and attaches it to the issue. You don't take screenshots. The agent does.
-
Vision model description. The screenshot goes through a vision model that writes a text description of what's on screen. Future-you searching the issue tracker for "floating tree" finds it even if the transcription was garbled.
-
Coordinates and context. The game engine provides the player's world position, camera angle, and current game state. The agent bakes these into the issue. A developer can teleport directly to the bug location.
-
Severity and routing. The agent estimates severity from context ("floating" is visual, "crash" is critical) and tags the right team member. An artist doesn't get pinged for a shader bug. A rendering engineer doesn't get pinged for a UI text overflow.
-
The numbers
-
| Method | Time from observation to filed issue | Information loss |
-
|—|—|—|
-
| Mental note → type later | 5-30 minutes | High (positions, steps, context) |
-
| Alt-tab → type immediately | 30-60 seconds | Medium (screenshots missed, flow broken) |
-
| Voice → agent pipeline | 2 seconds | Low (screenshot + position captured automatically) |
-
The throughput difference compounds. A 30-minute playtest session with keyboard-only bug filing might yield 3-4 issues, half of them vague. The same session with voice-to-agent produces 10-15 issues, all with screenshots, positions, and reproduction context.
-
Setup is simpler than you think
-
You need three things, all of which you probably already have:
-
1. A microphone. The one in your headset is fine. Transcription models handle suboptimal audio surprisingly well.
-
2. Transcription. Whisper runs locally and is free. Cloud APIs are sub-cent per minute. Both work.
-
3. An agent that speaks your game engine's API. If your engine has an HTTP interface for screenshots and game state, the agent can wire the rest together. If it doesn't — add one. It's a weekend project.
-
The agent itself doesn't need to be custom-built. Any coding agent with tool access can be told "watch the game, transcribe voice input, file issues in the tracker." It's a skill file, not a product.
-
What changes when you stop typing bugs
-
The most surprising effect isn't the speed. It's the coverage. When filing a bug costs two seconds of speaking, you file bugs you would have previously ignored. The minor visual glitch. The slight animation hitch. The UI element that's two pixels misaligned.
-
Individually these are low-priority. Collectively they're the difference between a game that feels polished and one that feels rough. And they only get caught when the cost of reporting approaches zero.
-
The second effect is that playtesting becomes a primary input channel. Instead of structured QA sessions with checklists and forms, you just play the game. The agent captures everything. When you're done, you have a list of filed issues with screenshots and context — generated from your spoken observations in real time.
-
Voice isn't a gimmick for game development. It's the input channel that matches the way we actually work — looking at the screen, noticing things, and talking about them. The tools exist. The latency is sub-second. The cost is negligible. The only thing missing is the habit.
-
-
We build Tinqs Studio — a game dev platform with built-in AI agents, git hosting, and creative pipelines. Ariki is the survival colony sim we're building with every tool described here.
+Total latency: under 2 seconds. You keep playing.
+``
+
+This isn't theoretical. The pipeline runs on our own game project, and it's caught bugs that would have slipped through playtesting entirely — the ones you see, make a mental note about, and forget by the time you alt-tab.
+
+## Why game dev is the perfect voice use case
+
+
You're already looking at the screen. Voice input doesn't require switching windows or breaking flow. You're playtesting — your hands are on the controller or WASD, your eyes are on the game. Speaking is the only input channel that doesn't interrupt the thing you're actually doing.
+
+
Game bugs are spatial and visual. "The crafting UI text overflows on items with names longer than 20 characters" is something you see, not something you calculate. Describing it verbally while looking at it produces a far richer bug report than typing from memory.
+
+
Reproduction is half the battle. When you speak the bug at the moment of occurrence, you naturally include the context: what you were doing, what just happened, what the game state was. You don't have to reconstruct it later.
+
+
Voice scales to the whole team. Artists see visual bugs. Designers see balance issues. Producers see UX friction. Not everyone on a game team is a fast typist or comfortable with issue trackers. Everyone can speak.
+
+## What the agent adds beyond transcription
+
+Raw transcription is useful — it's a notepad you don't have to type. But the agent layer is what makes voice input a pipeline rather than a dictation tool:
+
+
Screenshot coordination. The agent calls the game engine's HTTP API, captures the current frame, and attaches it to the issue. You don't take screenshots. The agent does.
+
+
Vision model description. The screenshot goes through a vision model that writes a text description of what's on screen. Future-you searching the issue tracker for "floating tree" finds it even if the transcription was garbled.
+
+
Coordinates and context. The game engine provides the player's world position, camera angle, and current game state. The agent bakes these into the issue. A developer can teleport directly to the bug location.
+
+
Severity and routing. The agent estimates severity from context ("floating" is visual, "crash" is critical) and tags the right team member. An artist doesn't get pinged for a shader bug. A rendering engineer doesn't get pinged for a UI text overflow.
+
+## The numbers
+
+| Method | Time from observation to filed issue | Information loss |
+|—|—|—|
+| Mental note → type later | 5-30 minutes | High (positions, steps, context) |
+| Alt-tab → type immediately | 30-60 seconds | Medium (screenshots missed, flow broken) |
+| Voice → agent pipeline | 2 seconds | Low (screenshot + position captured automatically) |
+
+The throughput difference compounds. A 30-minute playtest session with keyboard-only bug filing might yield 3-4 issues, half of them vague. The same session with voice-to-agent produces 10-15 issues, all with screenshots, positions, and reproduction context.
+
+## Setup is simpler than you think
+
+You need three things, all of which you probably already have:
+
+1.
A microphone. The one in your headset is fine. Transcription models handle suboptimal audio surprisingly well.
+2.
Transcription. Whisper runs locally and is free. Cloud APIs are sub-cent per minute. Both work.
+3.
An agent that speaks your game engine's API. If your engine has an HTTP interface for screenshots and game state, the agent can wire the rest together. If it doesn't — add one. It's a weekend project.
+
+The agent itself doesn't need to be custom-built. Any coding agent with tool access can be told "watch the game, transcribe voice input, file issues in the tracker." It's a skill file, not a product.
+
+## What changes when you stop typing bugs
+
+The most surprising effect isn't the speed. It's the coverage. When filing a bug costs two seconds of speaking, you file bugs you would have previously ignored. The minor visual glitch. The slight animation hitch. The UI element that's two pixels misaligned.
+
+Individually these are low-priority. Collectively they're the difference between a game that feels polished and one that feels rough. And they only get caught when the cost of reporting approaches zero.
+
+The second effect is that playtesting becomes a primary input channel. Instead of structured QA sessions with checklists and forms, you just play the game. The agent captures everything. When you're done, you have a list of filed issues with screenshots and context — generated from your spoken observations in real time.
+
+Voice isn't a gimmick for game development. It's the input channel that matches the way we actually work — looking at the screen, noticing things, and talking about them. The tools exist. The latency is sub-second. The cost is negligible. The only thing missing is the habit.
+
+—
+
+
We build Tinqs Studio — a game dev platform with built-in AI agents, git hosting, and creative pipelines. Ariki is the survival colony sim we're building with every tool described here.
+
+
{kind=link}